Hey there! I'm
Arnav Sharma
I like applying Machine Learning and Artificial Intelligence concepts on full-stack applications.
01.
About Me
Hey! I'm Arnav Sharma, and I'm currently pursuing a Bachelor's Degree of Science in Computer Science at The Pennsylvania State University. I love making projects where I apply Machine Learning or Artificial Intelligence concepts to create cool or useful features for full-stack applications.
I am constantly fascinated by the vast and evolving processes behind Machine Learning and Artificial Intelligence, and I am dedicated to lifelong learning in the field.
When I'm not coding, you can usually find me trying to cook up some new recipes, unwinding with a good TV show, or hiking a trail. I'm also a big fan of staying active by hitting the gym or playing sports like soccer and pickleball.

Some technologies I like to work with
02.
Experience

Software Engineering Intern
Wefire
Developed and deployed advanced Python-based programs that transformed 5,000+ Reddit posts into actionable financial insights, driving company publicity initiatives through sentiment analysis powered by Google Gemini API and Pandas. Created a high-performance real-time monitoring infrastructure using PRAW tracking brand mentions and sales keywords across multiple subreddits, generating 500+ instant alerts through an automated SMTP pipeline during 24-hour testing periods, resulting in 40% faster customer response times and enhanced brand reputation management.
03.
Projects

Automated Predictive Modeling Platform
Full-stack ML platform with FastAPI/Next.js serving non-blocking real-time inference APIs via Celery/Redis distributed compute. Features AutoPreprocessor reducing feature engineering time by 80%, Bayesian hyperparameter optimization (Optuna) for XGBoost/Random Forest/CatBoost/LightGBM, SHAP/LIME explainability, and MLOps workflows with Prefect orchestration and PostgreSQL/S3 version control.

Real-Time ASL Learning Platform
A real-time ASL learning platform with 98.98% accuracy PyTorch neural network converted to ONNX for <50ms browser inference. Features MediaPipe hand tracking for 60 FPS sign recognition of all 26 alphabet signs, FastAPI backend with Supabase database, user authentication, lesson modules, interactive quizzes, and progress tracking.

Resume Chatbot
An intelligent resume chatbot that allows natural conversations about professional background and experience. Built with Retrieval-Augmented Generation (RAG) technology using LangChain and OpenAI API for responses.
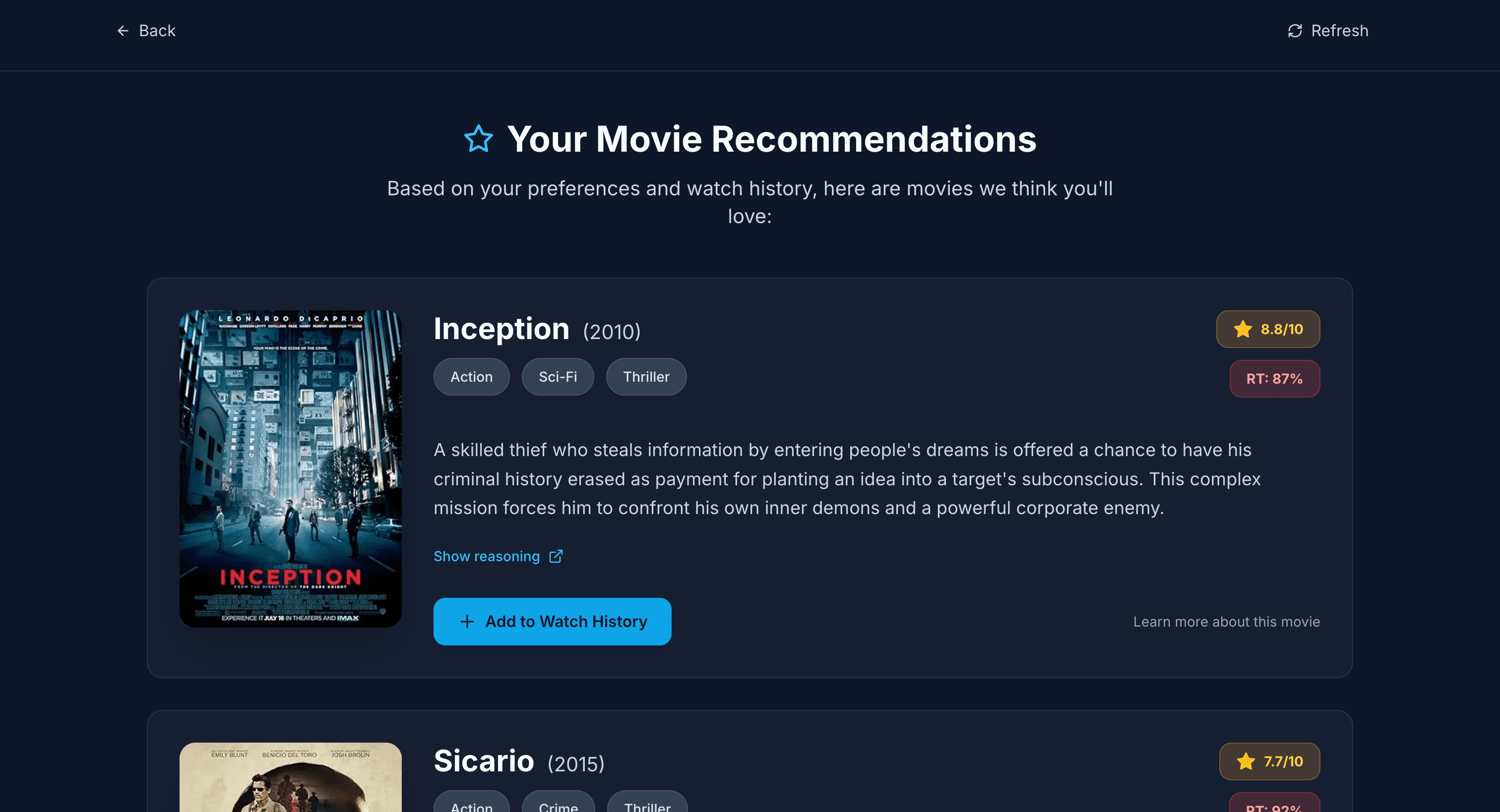
AI Movie Recommendation Engine
A movie recommendation platform powered by Google Gemini AI that provides personalized movie suggestions through an interactive questionnaire. Features watch history tracking, OMDB API integration for movie metadata, and a responsive UI built with Next.js and Tailwind CSS.

PSU Menu Analyzer Website
A full-stack web application that scrapes Penn State dining menus and provides AI-powered nutritional analysis. Features real-time menu updates, dietary filtering, and CSV export using Google Gemini API.
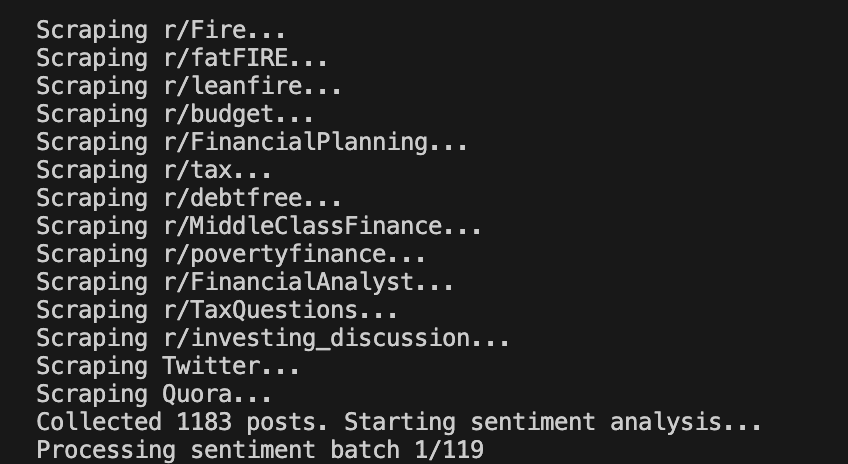
AI-Powered Reddit Post Analyzer
A Python tool that scrapes and analyzes up to 5,000 Reddit posts from financial subreddits to track market sentiment. Uses Google Gemini API for NLP classification and summary generation, with Pandas for data processing and structuring insights.

SubReddit Monitor & Notification Tool
An automated monitoring bot that streams Reddit posts in real-time using PRAW library and identifies relevant financial discussions. Sends instant email notifications via SMTP when keyword matches are found, enabling real-time market sentiment tracking.